What is a Data Lake
A Data Lake is a repository used for storing data in their native format and from diverse and inhomogeneous sources. The collected data are not transformed and their original structure is maintained. This allows companies to be able to organize and analyze their data, even large data, through a simplified management platform.
Data within a data lake are transformed only at the point when they need to be analyzed, and then a schema is applied to proceed with the analysis using a process referred to as “schema on read.”
How does a Data Lake work
- Collect: you collect data from multiple different sources (email, social media, spreadsheets, PDFs, etc.), which flow into the “lake” (lake). A data lake preserves and stores all data, regardless of structure or source.
- Ingest: data are collected in their original format and will be processed exclusively at the time they will be used (schema on read). In fact, there are no time constraints for data analysis.
- Blend: data are selected, combined with each other, and organized as the need arises.
- Transform: “raw” information is analyzed, refined, and transformed into the required data.
- Publish: data are finally processed and ready for publication.
- Distribute: data are distributed and shared through a wide variety of media.
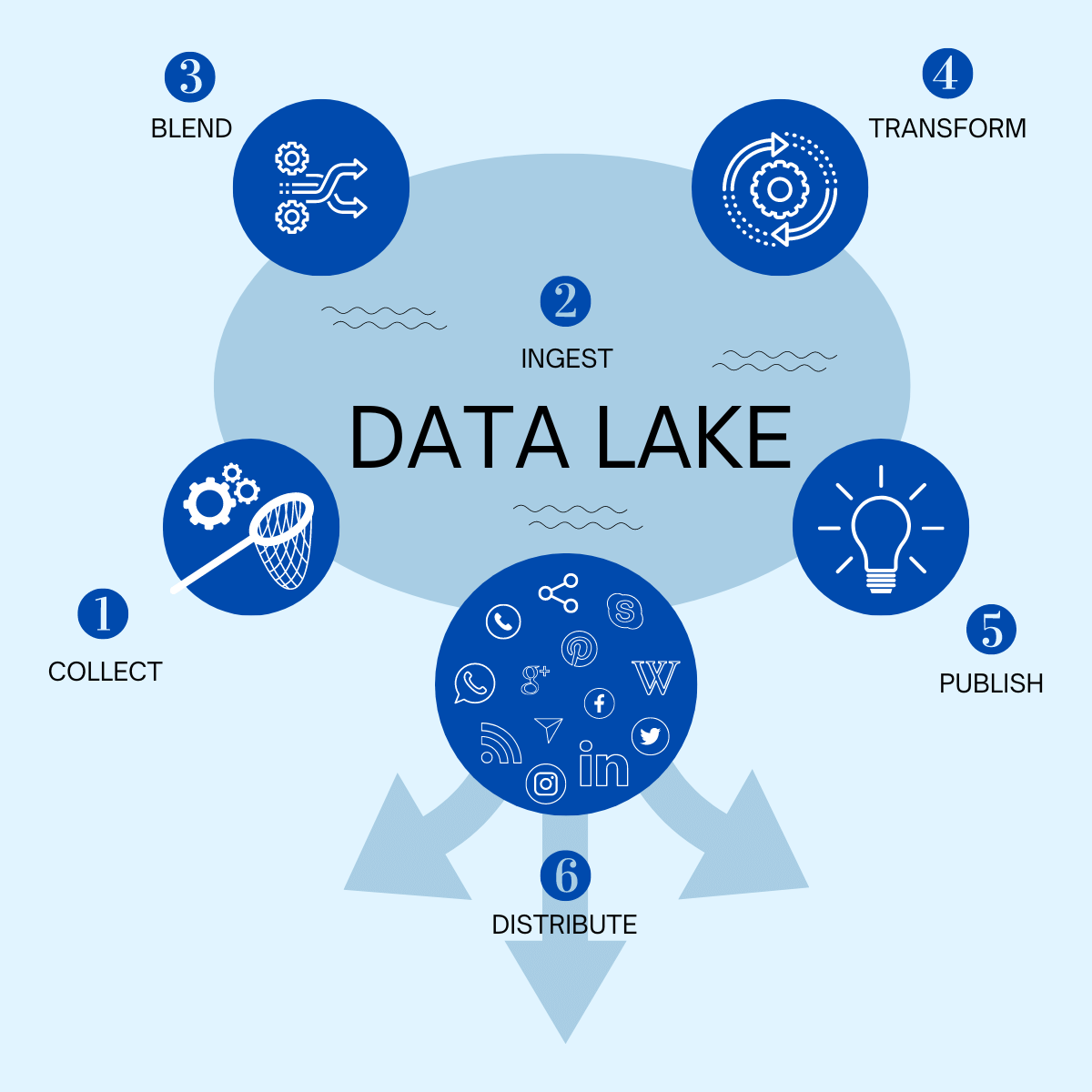
The data elaboration phases in a Data Lake
The difference between Data Lake and Data Warehouse
Unlike Data Lakes, in Data Warehouses the data is modeled before being stored, resulting in the data not being able to take full advantage of its value. In a Data Warehouses, the underlying model requires that the data be all structured, resulting in the need for processing of the data before it is written to storage through a process that is called “schema on write.”
This process that transforms data is often complex and time-consuming, prevents its immediate capture and requires hardware infrastructure specific to this type of storage that, in most cases, is more expensive than the one used in Data Lakes.
Access to data from a Data Lake allows data to be analyzed as is and without the need to move it from one system to another, performing processing directly on the repository. In order to make the data usable at all times, it requires continuous governance to prevent it from becoming inaccessible, cumbersome, expensive and, as a result, useless (data swamp). In terms of architecture, Data Lakes use a flat structure and are highly scalable, which becomes a key point of differentiation from the Data Warehouse, where traditional storage systems do not offer this kind of scalability. In fact, when creating a Data Lake, the volume of data that will be stored is not known in advance, and this requires infrastructure that can scale easily and quickly.
| Data Lake | Data Warehouse | |
|---|---|---|
| Data | Native format, structured, semi-structured and non structured | Elaborated and structured |
| Schema | Written in the reading and data analisys (schema on read) | Designed in repository building phase (schema on write) |
| Data Quality | Cured and raw data (not elaborated) | Cured and refined (elaborated) |
| Storage | Limited costs | faster queries based on a more expensive storage and high integration costs |
| Purpose | Defined or to be defined for a future use | defined |
Data Lake advantages
Data lakes allow you to expand the information sets you have access to. Data are collected from multiple sources and moved into the Data Lake in their original format, saving considerable time in defining data structures, schemas, and transformations. In addition, Data Lakes allow users with different organizational roles (data scientists, data developers, and business analysts) to access data by choosing their own analytical tools and frameworks.
Then there are numerous ways to query and analyze data, making them optimal for Modern BI applications, Machine Learning Operations, as well as for Visual Analytics operations and making enterprise projects in Artificial Intelligence operational and productive.
Storage costs are reduced because, compared with a traditional or Data Warehouse system, it is not necessary to predict in advance all future uses and methods of data access. The system can thus grow and scale as needed with significant savings in infrastructure costs and time required for data consolidation.



