NVIDIA OptiX is a ray-tracing API, with both CUDA and C/C++ side functions, which allows you to use the enormous potential of the ray-tracing cores of modern graphics cards in a very simple and efficient way. OptiX supports lightweight scene representation based on triangles, curves, spheres or user-defined primitives.
We wanted to investigate the applicability of NVIDIA OptiX, and of ray-tracing cores in general, to collision-detection (a rather unusual application for this technology). For this we used SOFA (framework for real-time simulations) and for SOFA we developed a plugin that implements a collision-detection pipeline that uses graphic cards equipped with ray-tracing cores using OptiX. This pipeline has to convert the SOFA data structures into much simpler structures (triangles in our case) that can be handled by OptiX.
We compared the times needed for the collision-detection of the developed plugin (optix) with 2 SOFA built-in pipelines: CPU (BruteForce + BVHNarrowPhase) and cuda. To carry out the comparison in a controlled way (the number of collisions to be detected is known at each step of the simulation) a very simple scene was considered: a certain number of cubes (decided at will) falling on another parallelepiped, the latter motionless. In this way we have that, with full or imminent contact, the number of collisions that must be detected by the 3 pipelines is always 4n, where n is the number of falling cubes and 4 are the lower edges of each cube. The 2 following figures show the scenes related respectively to 1 and 10 cubes.
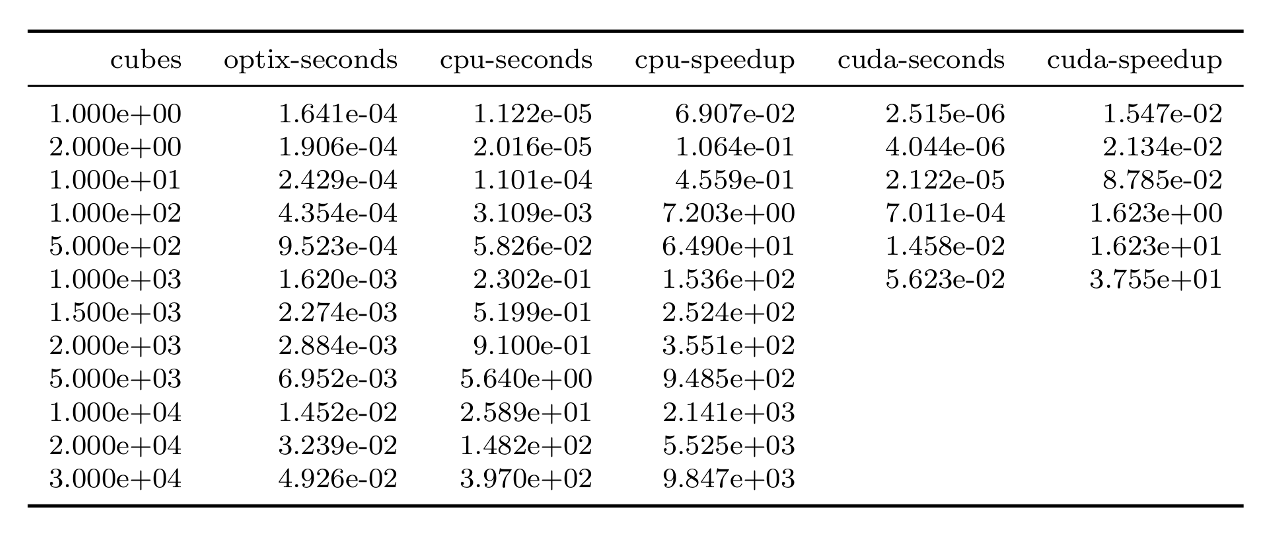
The results of the comparison are very positive and show how the collision-detection performed with the ray-tracing cores can be very advantageous compared to the 2 SOFA built-in solutions considered, cpu and cuda, with speedups that reach 1e4. The following table presents, for different values of the number of cubes (number of collisions), the results of the comparisons expressed in terms of time to perform the collision-detection (average over the 100 simulation steps performed) and in terms of speedup (built-in implementation time divided by the optix implementation time).
The following figures present the same results from the table in a graphical form, respectively in terms of execution time and in terms of speedup. As can be seen from the first figure, the computation time for the optix pipeline grows much slower with an increasing number of collisions than the other 2 pipelines. This causes the speedup (shown in the second figure) to grow very quickly as the number of collisions increases. The results of the cuda pipeline for more than 1e3 cubes are not reported as that pipeline for these values failed with a “cudaMalloc error out of memory”.
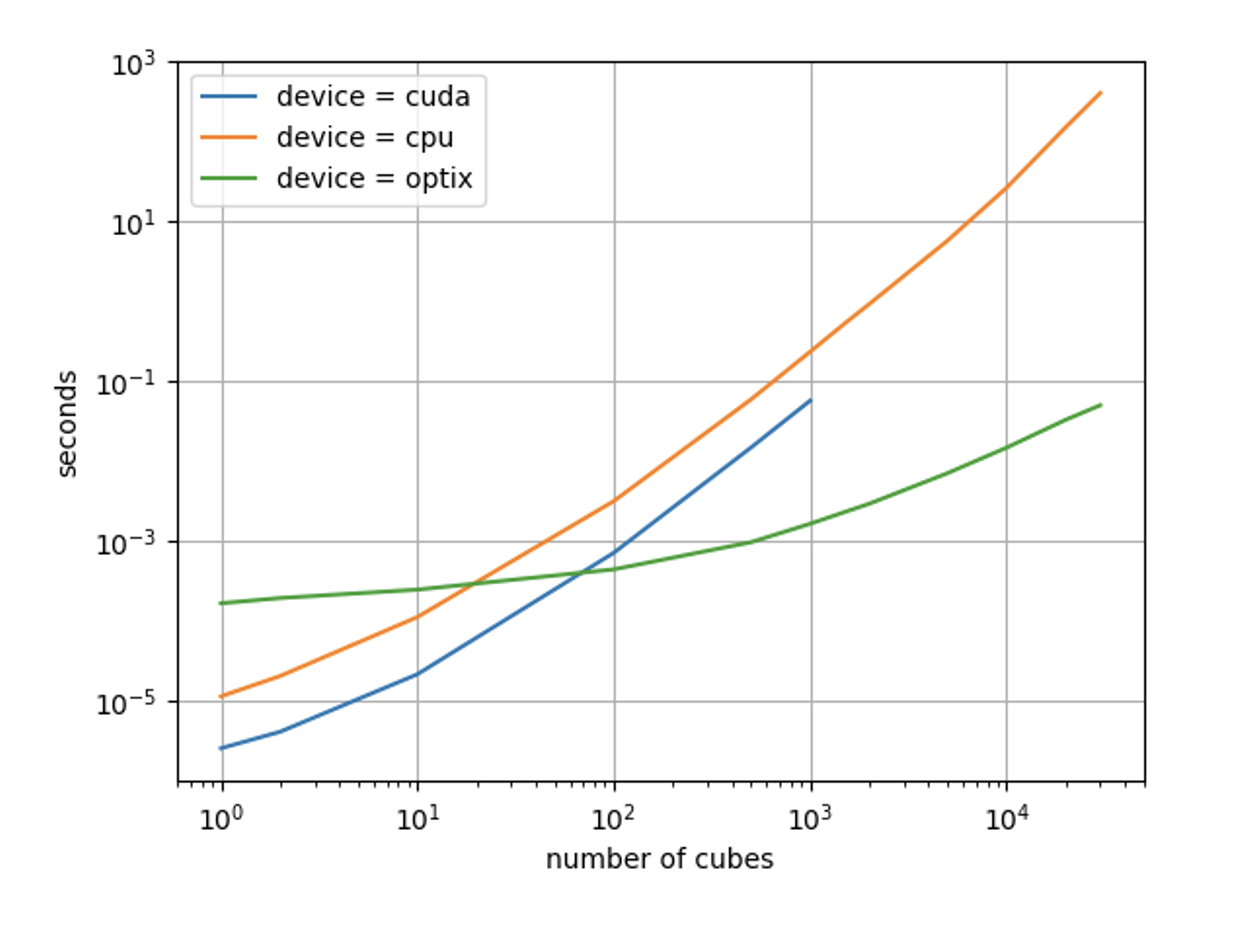
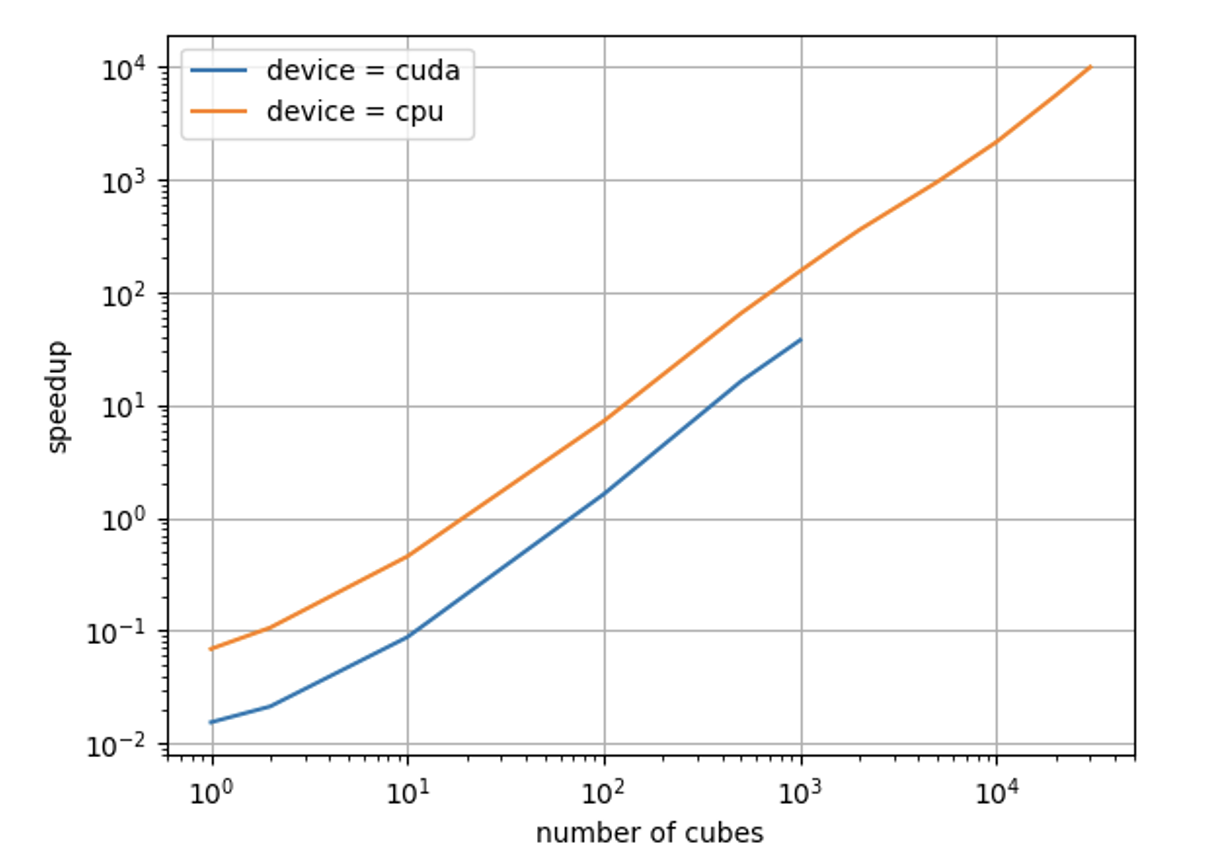
However, from the results it can also be seen that the optix pipeline is the slowest for low values of the number of collisions. This is easily explained considering the fact that the conversion of data structures between SOFA and OptiX, as well as the subsequent communication of these structures to the GPU, can be very time consuming, therefore not advantageous when the computational load for the GPU is low. This limit is not particularly worrying given the fact that it occurs in conditions of little practical interest (very small models) and could be mitigated by implementing a collision-model for SOFA such that the data structures necessary for collision-detection are already on the GPU (and in an appropriate format) at the beginning of the collision-detection phase.



